本文共 945 字,大约阅读时间需要 3 分钟。
上次文章中我们说到了redis复制的问题,大概得过程就是从节点会在启动的时候建立与主节点的通信,然后主节点将数据通过网络发送到从节点。但是考虑到数据拷贝是通过网络进行的,因此网络是一个潜在的瓶颈。除此之外从节点也可以拥有从节点,所以我们的数据复制貌似还挺复杂的,最终就会形成一个主从链。
考虑到上述我们说的redis复制链来说,如果有master、slavex、slavey的复制链。其关系如下:
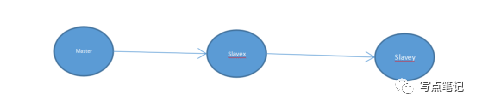
那么当slavex复制master的命令的时候,slavey将不会与slavex建立数据同步连接,最终slavey将尝试重新建立链接,只有链接建立成功之后才会将slavex的数据同步到slavey。也就是数据是从master节点不断的向下进行广播式的传递的。
但是考虑到有时候读多写少,而且负载的压力很大,那么单机就没有办法处理了,因此我们在master下边挂很多个从节点,让我们的从节点去分担读的压力,但是随着负载的逐步加大,写入的速度会随着从节点的变多而变慢,因此一个master节点不能无限制的添加从节点,为了解决这种写入慢的问题就可以通过添加一层中间层来解决,如下图所示:

当然为了解决上述的写入和读取的压力问题而构建的redis复制树并不一定是上图的样式,但只要能解决问题就行。
在之前我们说redis提供的aof文件可以将redis的数据丢失限制在一秒以内,但是如果我们同时采用复制的策略,那么我们可将我们的数据在多机的磁盘上进行保持,这样将更有利于数据的安全性。
当然如果我们使用aof策略,那么我们的从节点就应该开启aof文件。这块在前两篇文章已经讲过了。
但是问题就是当我们将数据写入master的时候,如何保证slave节点都有值?一种粗糙的方式就是间隔一段时间去检测一下,但是这种方式我们无法确定这个时间的片段应该为多少。这块我们可以通过日志aof_pending_bio_fsync来判断。这块书中提供了一个redis复制链的数据同步检测方法。注意这里建立了两个redis的信道,首先在master上对数据添加一个标志,然后轮询从节点的数据同步状态,然后查询从节点的接收的数据变化,最后通过aof_pengding_bio_fsync来判断数据是否进入了从节点的磁盘。

转载地址:http://rwumi.baihongyu.com/